PressBooks
On the 15th and 29th of April, 2014 I presented, with Clint Lalonde, some of the modifications that I’ve made to PressBooks and PressBooks Textbook:
Before I talk about the specific modifications that I made to PressBooks I’m going to create some context around them. One of the key elements that was in place before I began working on these features was PressBooks being released as open source software.
This project and the modifications I’ve made to PressBooks was only possible within that context. What we end up with is one of the best, web-based resources for open textbooks. And if I’m wrong about that, then I urge you to grab some developers and make it that way. We expect that once people more familiar with the functionality that PB offers in an academic setting, we’ll see more demand from institutions. Like open textbooks, open software started out as something cheap and ‘good enough’. Now, it drives innovation, offers higher quality software and gives us more control to meet our own needs.
We also know that while not every organization has a strong internal policy for contributing to and using open source software, some do, and because of the low cost barrier and open standards, there’s a better chance that an open source package will be integrated into an institutions’ existing architecture. PB can be installed on any LAMP stack, as long as your PHP version is greater than 5.4. It has four server dependencies that can be installed without any trouble.
So what modifications were made?
First we asked the question, what functionality does an open textbook require above and beyond the functionality that is required of a regular book? The other question we asked ourselves is, what happens when we develop features or functionality that deviates from the direction of pressbooks.com? Beginning with the second question, it’s important to remind ourselves that open source still requires infrastructure; servers, networks, and human resources to keep them running. An article in the Chronicle of Higher Education recently stated, “Open-source is not a free beer, it’s a free puppy”, implying once you get the free thing, there are still costs associated with maintaining it. Much like wordpress.com offers hosting and services around WordPress, Hugh McGuire, the founder of PressBooks and owner of pressbooks.com provides infrastructure and support services to authors who want to create and sell their books. In direct contrast to that, we want to give them away for free. So, what do we do? Where our use-cases deviate, I develop code in a separate plugin called PressBooks Textbook and where our use cases merge, I commit code back to PB core. That way, we can both continue to grow and scale our business objectives in symbiosis.
Let’s take a look at what that symbiosis looks like right now and what I hope will start to emerge is the answer to the first question: What functionality does an open textbook require that is different than a regular book. The PressBooks Textbook plugin uses a familiar framework in the OER world to contextualize what is available to the user. The four R’s. (and one ‘O’).
Reuse
this tab displays the option to include creative commons licensing on every page so that you can indicate that the content you create is available for reuse. You’ll notice right away that our plugin also includes other plugins, written by other people. In some cases I modify the plugin before I can get it to work in the PressBooks environment and in other cases, it is used straight out of the box.

The Creative Commons Configurator plugin didn’t come with an ability to appropriately cite a derivative work which was critical for us. So, I used George’s code, added my own functionality and included it all in my plugin much like what is possible with open textbooks.
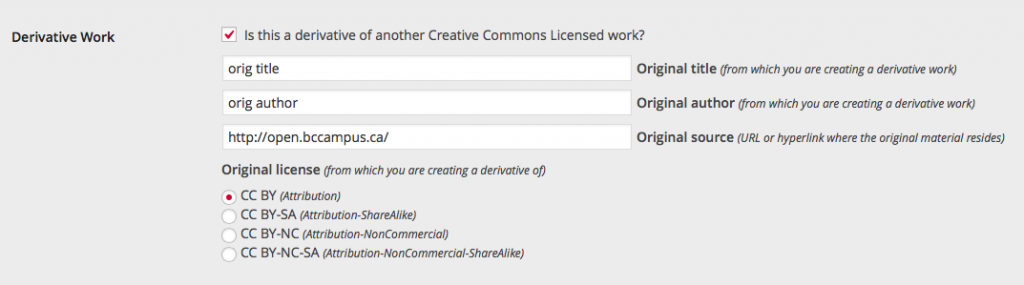
After I go through the other features of the plugin I’m going to take a couple minutes to show you what reusing a few chapters looks like using some of the features that we’ve built. When I compare the workflow of reusing code to reusing parts of a textbook, I begin to see some solutions that we could consider borrowing. I’m curious about some github-esque features we can incorporate into pressbooks including the ability to fork a book, or a chapter and immediately bring it into an editing environment. I’m also curious about what kind of ecology it would create if each institution either had access to an instance of PB, or hosted their own instance of PB.
Revise
The bulk of this functionality is already supported by the editing capabilities of WordPress and PressBooks but the parts that were missing for us are the ability to add math equations, tables, learning objectives, exerices and key takeaways.

Introducing most of these features was pretty straight forward, but the challenge is always to make it persist, and be consistent throughout each export file. The limitations of a made for print format such as a PDF always present challenges when including features in a dynamic environment such as the web. Math equations, for instance, are very easily rendered in a browser using a markup language called LaTeX and a javascript library called MathJax. However, in a static, print format such as PDF, this is just not possible. To work around that, we use a LaTeX image rendering service so that math equations are displayed as images and can show up on a web page, epub, or pdf file. I’ll show you some code in a minute that takes a look at how that’s implemented. One of the ways that I’ve been working towards making video and audio resources persist throughout the export routine is working with a guy in the States to create a new module that exports to a backwards compatible EPUB3 format. If you don’t already know the EPUB 2 spec does not permit these types of files and there is varying degree of support for EPUB3 files in the array of tablets, and EPUB readers on the market. A way around that is to make it an EPUB 3 document that is backwards-compliant to EPUB 2 specs, and where devices support audio and video, they will be available to the end user. I’m happy to announce that as of a couple weeks ago, our code contributions were merged into PB core and we’re now hoping to get some feedback so we can refactor and iterate. The EPUB3 spec also supports a markup language for math equations called MathML, but again the question is how do you get MathML to render as an equation in a static PDF? I still haven’t figured that out, so let’s take a look at the code and see where we’re at with math equations.

First we have to get an image which we can do by passing a LaTeX formula as an argument to the latex image rendering service, which is what we see at the top.

We generate a url, it gives us an image. The difference is in the naming convention of the image that is returned, which breaks the are-you-really-an-image test in PB. Most links to images consist of a path to the file, the filename and the suffix representing the type of image, be it .png, or .jpg. What the image rendering service gives us is a long, nasty url without a image suffix. So, this is where we force an exception in the export routine when it comes along and scrapes all the remote media resources so that we can shove them into the zip file, or EPUB document.
Remix
This is the most exiting one and where most of the work I’ve done so far has been focusing on.
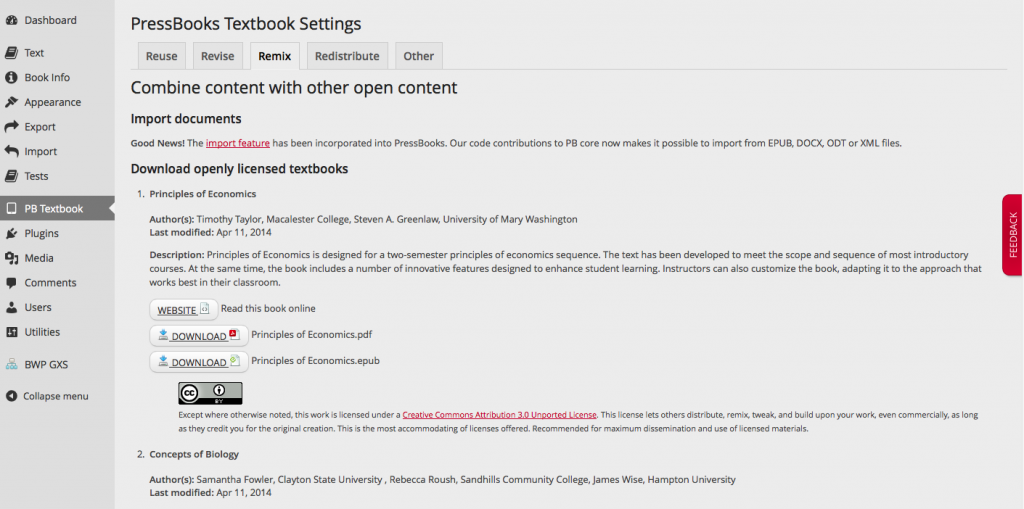
PressBooks had no import functionality when it was first released yet it was critical for our primary use case. There were a lot of books in the commons that were available in different digital formats and the whole notion of remixing depended on taking parts of something and easily putting them into something else. Copying and pasting is always an option, but it doesn’t bring over images, and it’s pretty labour intensive so there was a lot of motivation to build something that was easy to use and offered something more. So, I started working with a guy in Germany on building an EPUB importer. Later I built and submitted back to PB core the DOCX and ODT import functionality and Dac Chartrand, formerly of PressBooks, built the WordPress XML importer. More recently, we wanted to put open textbook resources right in front of the user in the same environment that they’d be remixing in, so I enabled the ability to download any of the 51 open textbooks that we currently have in our repository. Many of those textbooks are offered in WORD, or DOCX format and in order to be able to push that button, we need to import them into HTML.

The first thing to know is a DOCX file is also, just a zip file. The process of extracting the content from a DOCX file comes down to understanding the file structure within it and then parsing the content from the very bloated, barely-human readible XML format that Microsoft uses to represent content. Nevertheless, here’s some of the code for extracting and parsing a DOCX file, which is similar to the code for an EPUB and ODT file.
Redistribute/Retain:
This one is pretty cool too, for a couple of reasons. First, implementing the solution got me thinking about how I could also implement giving these textbooks an API.
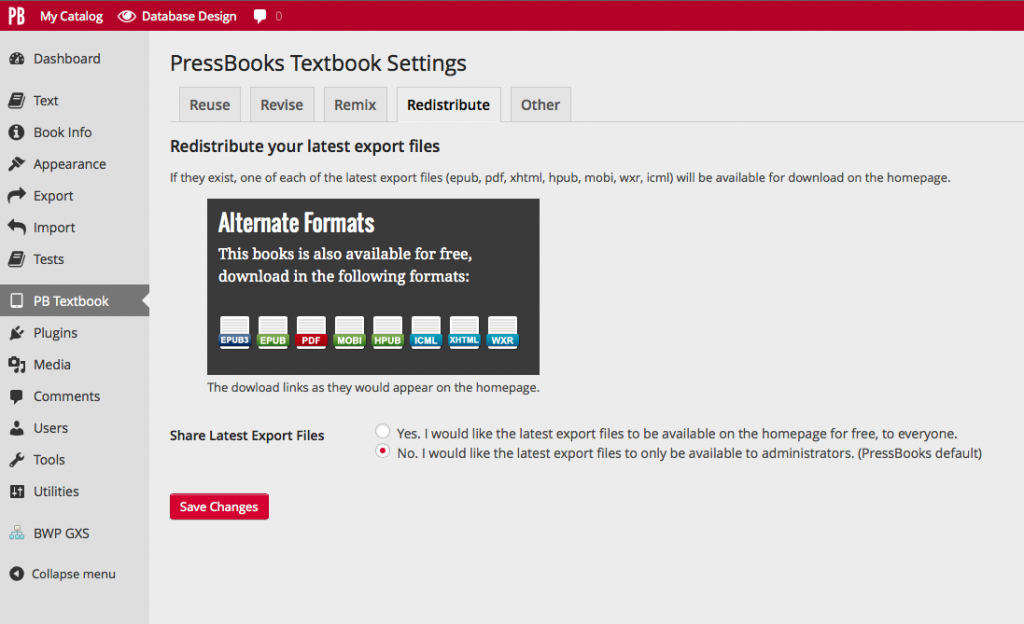
WordPress endpoints will be another fantastic way to enable a redistribution of sorts. We can consider extracting and parsing different metadata from the textbook in either a JSON or XML format with relative ease. The question then becomes what metadata is important in an educational context and what purpose will it serve? All this to say finding out about WordPress ‘endpoints’ as part of the ReWrite_API was a really cool ‘a-ha’ moment for me and I can’t wait to exploit it. Second, the solution I came up with to distribute files for free in a protected environment had to be executed in a way that didn’t undermine the core business of pressbooks.com. The functionality of the redistribute feature boils down to, if they exist, one of each of the latest export files (epub, pdf, xhtml, hpub, mobi, wxr, icml) will be available for download on the homepage. Once someone downloads the file, it’s theirs to keep and do what they will.
WP has made it easy to reserve a URI. The URI, or endpoint that I’ve reserved for free downloads, is the word ‘open’. Instead of resolving to a directory location, we are redirected to a function, which I’ve called ‘do_open’.

The function ‘do_open’ evaluates filename and filetype variables that were passed in the URI and returns header information which initiates a file download.
The exciting part about knowing that we can reserve an endpoint and have it redirect to a function means that what is returned is limited only by what we can get a function to do. I know that querying the database and extracting book information, or metadata is trivial, so choosing a schema and formatting the response in either JSON or XML are the only tasks left after that. This means that each book can expose information about itself depending on the need or particular use case.
Now we’ll take a look at what remixing a chapter looks like using some of the features that we’ve built. So, in the spirit of twitch.tv where people watch other people play video games online, but without the commentary, we’re going to watch a screen capture! I’ve downloaded the file and decided that I need a few chapters from Rajiv’s book but in a different order that they appear in the original book.